Créez, gérez et partagez vos métadonnées avec Maggot
Dans ce retour d’expérience, nous mettons en lumière l’importance d’une bonne gestion des données et de leurs métadonnées dans le domaine scientifique. Découvrez comment Maggot simplifie la saisie et le transfert des métadonnées vers différents systèmes d’information en s’appuyant sur les schémas standards et les vocabulaires contrôlés.
Sommaire
Au sein des collectifs (unités, plateformes, grands projets, etc.) se posent les défis d’organisation, de documentation, de stockage et de partage des données afin d’avoir une visibilité sur ce qu’ils produisent : jeux de données, logiciels, bases de données, images, sons, vidéos, analyses, codes, etc. Les métadonnées (littéralement, les « informations sur les données ») jouent un rôle essentiel tout au long du cycle de vie de la donnée mais leur capture et leur partage restent encore souvent problématiques.
Capturer les métadonnées, une tâche ingrate mais essentielle
Le partage des données suscite encore beaucoup de réticences, parfois justifiées, mais qui masquent parfois un manque de volonté. Pour y pallier, il faut créer une culture de partage des métadonnées. En effet, les métadonnées décrivent des informations pertinentes sur les données en leur donnant plus de contexte pour les utilisateurs, et sont par ailleurs moins sensibles que les données. C’est aussi et surtout une des conditions préalables vers une science ouverte.
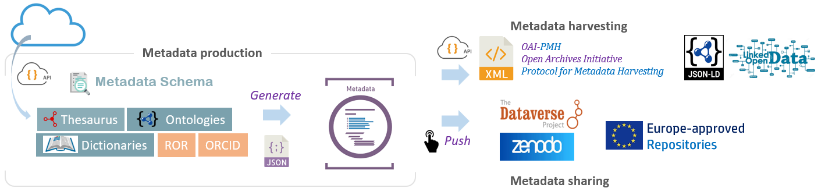
Il s’agit d’abord de favoriser une bonne gestion des données, tout en gardant à l’esprit le partage des métadonnées. Pour cela, nous proposons l’outil Maggot (à gauche dans la Figure 1) qui permet de construire des ensembles de métadonnées adaptées à l’aide de différents vocabulaires contrôlés et de les envoyer vers divers entrepôts et catalogues de données comme Recherche Data Gouv, l’entrepôt national basé sur la technologie Dataverse ou Zenodo, l’entrepôt pluridisciplinaire lancé en 2013 pour soutenir la politique d’Open Access et d’Open Data de la Commission européenne.
Une approche progressive pour apporter sémantique et interopérabilité
Une des préoccupations principales du travail s’est focalisée sur comment « capturer » les métadonnées le plus facilement possible en mobilisant le référentiel de vocabulaire des utilisateurs, puis de les structurer pour 1) la transparence et la reproductibilité, 2) la réutilisation. Concernant ce dernier point, il y a la visée de pouvoir faire un jour des méta-analyses à grandes échelles.
L’organisation des métadonnées devant suivre un schéma (c.à.d. indiquant quelles métadonnées sont attendues), celui proposé se base sur l’entrepôt de données Recherche Data Gouv [1]. C’est ce schéma par défaut que nous préconisons d’utiliser. Il est néanmoins possible de l’adapter (étape 1 dans la Figure 2).
Concernant la sémantique pour les valeurs des métadonnées, nous préconisons une approche progressive vers l’adoption de vocabulaires contrôlés standardisés (étape 2). Par exemple, un simple dictionnaire métier utilisé par la communauté dans le domaine scientifique concerné peut parfaitement suffire. Par la suite, la création d’un thésaurus peut être envisagée ou mieux encore, enrichir ceux existants (e.g. Thésaurus INRAE [3]).

Les métadonnées ainsi produites servent d’abord à alimenter un entrepôt local de données destiné à être consulté par l’ensemble des personnes du collectif. D’où l’importance, à la fois du schéma de métadonnées et des référentiels terminologiques propres à chaque collectif. Mais ces mêmes métadonnées peuvent aussi venir alimenter d’autres entrepôts, à savoir Recherche Data Gouv [1] et Zenodo [4]. De même, ces métadonnées doivent pouvoir être moissonnées en vue de faire des méta-analyses. Il est donc nécessaire de mettre en place des passerelles entre les différents formats [5].
S’appuyer sur les portails de vocabulaires et leurs APIs
Il existe trois grandes classes de vocabulaires : les thésaurus, les ontologies, ainsi que les vocabulaires non-hiérarchisés sous forme de simple liste (e.g. Découpage Administratif [6]). Ces vocabulaires étant mis à disposition sur Internet via des portails dédiés, et compte-tenu des volumes de données que cela représente, l’option choisie est de les récupérer à la demande à l’aide d’un connecteur sur ces portails – via des API (Application Program Interface [7]).
Parmi les portails supportés, on peut citer ceux basés sur OntoPortal [8] – comme AgroPortal [9] et BioPortal [10], ceux basés sur SKOSMOS [11] (e.g. Thesaurus-INRAE [3] , LOTERRE [12]) ainsi que le portail de l’EMBL-EBI (Ontology Lookup Service [13]). Alors qu’un portail de type SKOSMOS n’est dédié qu’aux thésaurus, ceux de type OntoPortal peuvent héberger tant les thésaurus que les ontologies. Le support de tous ces portails permet ainsi une grande diversité de choix dans les vocabulaires. Bien évidemment, quand elles sont existantes, les ontologies du domaine peuvent être choisies en sélectionnant celles qui sont réellement pertinentes pour le collectif et en dressant un paysage compréhensible du contexte dans lequel elles s’inscrivent. Une méthodologie est proposée sur le site du projet [2].
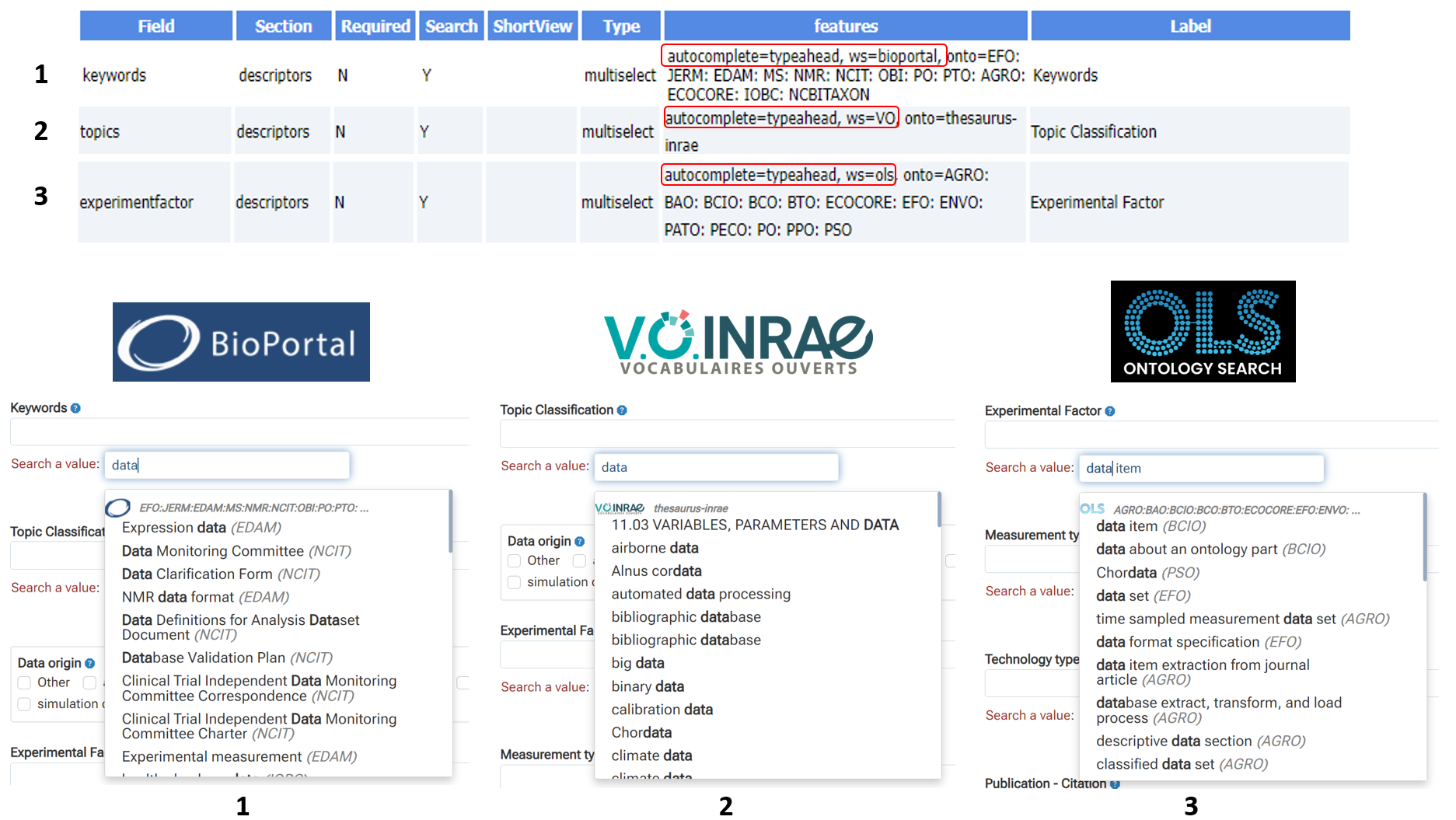
D’autres ressources annexes mais utiles sont aussi mobilisées (via leur API), afin de minimiser les saisies et donc les erreurs d’identifications, mais aussi d’éviter les doublons. On peut citer par exemple le registre des institutions à l’échelle internationale (Research Organization Registry [14]), ou encore le registre des identifications persistantes pour les personnes (ORCID [15]).
Concernant le moissonnage des métadonnées, qui consiste à collecter les métadonnées via une API en vue de les stocker sur une autre plateforme, le choix s’est porté sur le protocole standard OAI-PMH (Open Archives Initiative – Protocol for Metadata Harvesting [16]) basé sur le schéma de métadonnées DublinCore [17]. De même, les métadonnées peuvent aussi être moissonnées au format JSON-LD [18] basé sur le schéma de métadonnées schema.org [19]. Dans ces deux cas, des passerelles – metadata crosswalk [5] – ont été mises en place.
Retour d’expérience : les défis et les solutions pour une science ouverte
Des métadonnées plus FAIR...
L’outil a été mis en place pour des plateformes comme la Plate-Forme d’Infectiologie Expérimentale [20], pour des grands projets (e.g. GPR – Bordeaux Plant Sciences [21]), ou des unités de recherche (e.g. BFP [22], BIOGECO [23] ou AGAP [24]), pour ne citer que quelques sites pionniers.
Sur tous ces sites, cela a permis d’obtenir des métadonnées respectant mieux les principes FAIR [25], sans pour autant que les producteurs de ces métadonnées en soient toujours pleinement conscients. Ceci a répondu parfaitement à un objectif qui est de répartir les préoccupations entre les différents acteurs (gestionnaires de données, producteurs de données, curateurs de données) selon leurs compétences et leurs responsabilités [26].
Un collectif n’implique pas forcément et de loin, un même domaine d’étude, aussi observe-t-on une grande hétérogénéité des jeux de données au sein d’un même collectif. Aussi, un entrepôt de données géré en local, c.à.d. en intranet, avec des métadonnées mieux structurées et référencées est déjà une grande avancée vers la science ouverte mais ne sera pas forcement prometteur en termes de méta-analyses. Pour cela, il faut viser soit des entrepôts par domaine, soit une fédération d’entrepôts permettant de croiser les données pour un même domaine. D’où encore une fois, l’importance de bien choisir son référentiel de vocabulaire à partir de consensus établis au sein des communautés de chaque domaine.
Au moment de publier les données, les fichiers de données et les métadonnées peuvent être versés facilement dans un entrepôt de données comme Recherche Data Gouv ou Zenodo, car aucune ressaisie n’est nécessaire. Aussi, cela favorise davantage l’ouverture de ces données en sachant que le dépôt ne demandera que quelques secondes. En conséquence, un entrepôt comme Recherche Data Gouv pourrait être prometteur pour faire des méta-analyses, à condition une fois de plus que les métadonnées d’un même domaine soient cohérentes, c.à.d. utilisent les mêmes référentiels de vocabulaire.
...tout en ayant une approche pragmatique
La gestion des données est encore très loin d’être une préoccupation majeure dans les collectifs, même lorsque cela est affiché comme un objectif à atteindre dans le cadre de politique de données, souvent incluse dans une démarche qualité. C’est pourquoi il faut souvent insister sur le fait que « Open Data » ne veut pas dire « Open Bar ». Les métadonnées seules peuvent très bien suffire, à condition toutefois de préciser à quelles conditions les données sont accessibles. Il est donc urgent de développer la culture du partage des métadonnées.
Par ailleurs, en réponse au temps dédié à cette tâche, il faut répondre par des outils qui simplifient au maximum la saisie. Par exemple, il est plus facile de sélectionner un terme dans une liste déroulante reposant sur un vocabulaire métier que de choisir parmi une multitude d’ontologies. Il n’est donc pas étonnant que la plus grande difficulté rencontrée par les différents sites ait été sans conteste le choix d’un vocabulaire contrôlé de référence. En effet, il est fréquent que l’on ne puisse pas trouver au sein d’un thésaurus, d’une ontologie, ou même d’un ensemble d’ontologies, tous les termes souhaités pour décrire une métadonnée. Notamment, beaucoup de termes métiers sont absents de ces référentiels.
La solution consiste dans ces cas à créer un dictionnaire regroupant tous les termes souhaités en y mixant ceux provenant d’une ou plusieurs ontologies, ceux provenant de thésaurus, ainsi que les vocabulaires métiers. Ce qui constitue une sorte de nouveau mini-thésaurus. Il faut donc un gestionnaire de données qui, en amont, fasse ce travail de compilation et constitue ainsi un vocabulaire contrôlé de référence, et évoluant dans le temps, s’inscrivant dans un processus d’amélioration continue.
Perspectives
La « capture » des métadonnées étant cruciale, elle doit se faire idéalement de manière unique et à l’étape du cycle de vie de la donnée la plus pertinente concernant chacune d’elles. Par exemple, le nom d’un projet doit être enregistré au moment de son dépôt auprès des financeurs. Il en va ainsi tout au long du projet de recherche : la description du projet, des participants, avec des mots-clés généraux (ressources type ANR), puis ensuite vient le plan de gestion de données (PGD [27]) où l’on décrit les types de données, les licences, … (e.g. DMP Opidor [28]) puis les métadonnées propres à chaque expérimentation (e.g. Maggot [29]), et enfin les métadonnées structurelles de chaque jeu de données (e.g. ODAM [30]), jusqu’à la diffusion finale (e.g. Recherche Data Gouv. [1]).
Chaque saisie peut être source d’erreur, de confusion ou de doublon. C’est pourquoi, il faut renforcer la tendance à interconnecter les différentes ressources en ligne au sein d’un flux d’information suivant une logique d’étapes.
Ainsi, il est crucial de permettre la récupération des métadonnées tout au long du cycle de vie des données et de les transmettre avec une valeur ajoutée à chaque phase. Ce principe, appelé « machine actionnable », garantit l’exploitabilité des données par les machines [31], en utilisant des schémas de métadonnées standardisés et des vocabulaires contrôlés et partagés.
Pour en savoir plus sur le projet
Documentation et contacts : https://inrae.github.io/pgd-mmdt/
Daniel Jacob, François Ehrenmann, Romain David, Joseph Tran, Cathleen Mirande-Ney, Philippe Chaumeil, An ecosystem for producing and sharing metadata within the web of FAIR Data, GigaScience, Volume 14, 2025, giae111, DOI:10.1093/gigascience/giae111
- https://recherche.data.gouv.fr/
- https://inrae.github.io/pgd-mmdt/chats/chat3/
- https://consultation.vocabulaires-ouverts.inrae.fr/thesaurus-inrae/fr/
- https://zenodo.org/
- https://inrae.github.io/pgd-mmdt/chats/chat4/
- https://geo.api.gouv.fr/decoupage-administratif
- https://fr.wikipedia.org/wiki/Interface_de_programmation
- https://ontoportal.org/
- https://agroportal.lirmm.fr/
- https://bioportal.bioontology.org/
- https://skosmos.org/
- https://loterre.istex.fr/fr/
- https://www.ebi.ac.uk/ols4/
- https://ror.org/
- https://orcid.org/
- https://www.openarchives.org/pmh/
- https://dublincore.org/
- https://json-ld.org/
- https://schema.org/
- https://pfie.val-de-loire.hub.inrae.fr/
- https://sciences-environnement.u-bordeaux.fr/plateformes-programmes/GPR-BPS
- https://bfp.bordeaux-aquitaine.hub.inrae.fr/
- https://biogeco.hub.inrae.fr/
- https://umr-agap.cirad.fr/
- https://openscience.pasteur.fr/2024/09/27/les-principes-fair-findable-accessible-interoperable-reusable/
- https://inrae.github.io/pgd-mmdt/chats/chat1/
- https://coop-ist.cirad.fr/gerer-des-donnees/rediger-un-pgd/1-qu-est-ce-qu-un-pgd
- https://dmp.opidor.fr/
- https://inrae.github.io/pgd-mmdt/
- https://inrae.github.io/ODAM/
- https://ds-wizard.org/machine-actionability
INRAE (2025), Créez, gérez et partagez vos métadonnées avec Maggot, Vocabulaires Ouverts@INRAE, https://istblogs.d-marheine.com/lovinra/un-ecosysteme-pour-produire-et-partager-des-metadonnees
Daniel Jacob, Unité BIA.
Sophie Aubin, Magalie Weber
Date de création : 19/09/2025