Le Web sémantique et la représentation des connaissances
Le Web sémantique est souvent présenté comme une extension du Web. Son but est de fournir un cadre homogène de description et d’interrogation de sources de données hétérogènes afin d’améliorer la découverte de connaissances.
Principes et standards du Web sémantique
Selon le World Wide Web Consortium (W3C), « le Web sémantique fournit un modèle qui permet aux données d’être partagées et réutilisées entre plusieurs applications, entreprises et groupes d’utilisateurs ». L’expression a été inventée par Tim Berners-Lee dans un article publié dans la revue Scientific American en 2001.
Les standards du Web sémantique sont organisés selon une architecture validée par le W3C à l’aide d’un ensemble de couches indépendantes qui s’interfacent les unes avec les autres pour réaliser différentes tâches comme la représentation, les interactions, le raisonnement, l’interrogation, la mise en place de règles et la confiance comme le montre la Figure 1.
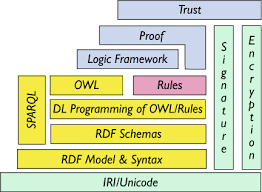
Figure 1: Architecture du Web sémantique
Le Web sémantique propose des langages spécialement conçus pour les données : RDF (Resource Description Framework), RDF Schema (RDFS), OWL (Web Ontology Language) et SPARQL (SPARQL Protocol and RDF Query Language).
Le premier principe du Web sémantique repose sur un standard du Web qui définit des IRIs, Internationalized Resource Identifiers (en français « identifiants de ressource internationalisés »). Les IRIs s’appuyent sur Unicode, un standard qui permet des échanges de textes dans différentes langues, à un niveau mondial et généralisent les URIs, Uniform Resource Identifiers (en français « identifiants uniformes de ressource »). Les URIs sont une extension du standard URL, Uniform Resource Locator (adresse web). Ainsi, tout ce qui est identifié par un URI est une ressource du Web, accessible sur le Web, et qui peut être décrite. Cela englobe les documents du Web (identifiés par leur URL) mais aussi toutes les autres choses, matérielles ou abstraites, dont on parle sur le Web, par exemple une table, une voiture, une plante, un humain, une organisation, ou encore une idée, un concept abstrait.
Le modèle RDF est l’élément central du Web sémantique. Il est conçu pour être utilisé par des applications qui doivent traiter le contenu de l’information au lieu de simplement présenter l’information aux humains. Les descriptions sont exprimées sous forme de graphes, composés de triplets « sujet-prédicat-objet » eux-mêmes désignés à l’aide des URIs/IRIs et interrogeable à l’aide du standard SPARQL.
RDFS (RDF Schema) et OWL (Web Ontology Language) étendent le langage RDF en fournissant des formalismes permettant la représentations d’ontologies avec des niveaux d’expressivité croissants.
- RDFS sert à décrire des vocabulaires simples : il permet de déclarer des types de ressources, c’est-à-dire des classes, comme les classes « personne » ou « document », et des types de relations entre les ressources, par exemple la relation d’auteur entre une personne et un document ;
- OWL quant à lui est plus expressif : il permet notamment de définir des classes par des conditions nécessaires et suffisantes pour appartenir à une classe.
Les données liées (Linked data)
Les données liées s’appuient sur les principes du Web sémantique : des URIs pour nommer les choses, RDF pour décrire les données et SPARQL pour les interroger. Quand les données sont librement accessibles sur le Web, on parle de Linked Open Data (LOD).
Lors de la mise en œuvre du partage des données, il existe différents paliers pour atteindre les données liées. En 2010, Tim Berners-Lee a proposé un système de notation à 5 étoiles pour évaluer la qualité des données ouvertes sur le web. Ainsi, on peut passer de données non structurées vers des données structurées décrites par une structure logique et des métadonnées associées comme indiqué sur la Figure 2.
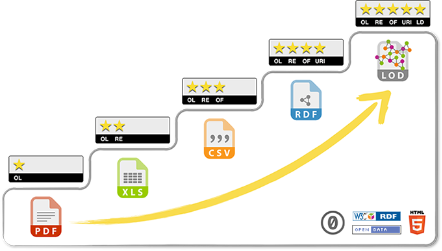
Figure 2 : Echelle « 5 étoiles » des données liées.
- 1 étoile : les données sont librement accessibles dans un format non structuré tel que le format PDF.
- 2 étoiles : les données sont disponibles dans un format structuré, tel que le format de fichier Microsoft Excel (ou autre format tabulaire).
- 3 étoiles : les données sont disponibles dans un format structuré non propriétaire, tel que le format CSV (ou autre format texte délimité).
- 4 étoiles : les données respectent les normes du W3C en utilisant le langage RDF et des identifiants URI ou IRI.
- 5 étoiles : tous les critères précédents, plus des liens vers d’autres sources de données ouvertes liées.
La clef du liage des données du Web, ce qui permet d’éviter d’avoir des silos de données, c’est-à-dire des sous-graphes RDF non connectés, c’est l’utilisation de vocabulaires communs partagés pour décrire les données. Ces vocabulaires sont souvent le résultat de travaux au sein de différentes communautés spécifiques et décrivent un domaine ou sous-domaine particulier, par exemple le Dublin Core pour décrire les métadonnées associées à des documents ou encore le vocabulaire FOAF (Friend of a friend, littéralement «l’ami d’un ami ») pour décrire les relations sociales entre les personnes. Le W3C a également proposé le standard SKOS (Simple Knowledge Organization System) pour décrire la partie terminologique des vocabulaires.
Représentation des connaissances
La représentation des connaissances désigne un ensemble de procédés destinés à encoder et à stocker des connaissances, de manière à ce qu’elles puissent être utilisées par un système d’intelligence artificielle.
Les connaissances sont généralement stockées dans une base de connaissances (Knowledge Base ou KB) qui utilise un modèle de données structuré en graphe appelé graphe de connaissances (Knowledge Graph ou KG).
En tant que composante de la base de connaissances, les ontologies constituent des ressources très utiles pour de nombreuses applications d’intelligence artificielle. En effet, l’ontologie fournit une structure et un contexte pour les données, ce qui donne un sens aux informations véhiculées par ces données et permet d’améliorer l’analyse et la prise de décision. Les ontologies peuvent aussi être utilisées pour améliorer diverses tâches basées sur l’apprentissage automatique, comme améliorer la précision et la cohérence des données d’entraînement. Pour pouvoir exploiter toute la puissance de raisonnement des ontologies, il faut néanmoins que leur conception respecte un certain niveau de formalisme logique.
- Corcho, O., Poveda-Villalón, M., and Gómez-Pérez, A., (2015), Ontology engineering in the era of linked data. Bul. Am. Soc. Info. Sci. Tech., 41: 13-17. https://doi.org/10.1002/bult.2015.1720410407
- Hitzler, P. (2021). A review of the semantic web field. Communications of the ACM, 64(2), 76‑83. https://doi.org/10.1145/3397512
- Hitzler P, Janowicz K, Tudorache T. Ontology engineering: Current state, challenges, and future directions. Semantic Web. 2019;11(1):125-138. https://doi.org/10.3233/SW-190382
- Berners-Lee, Tim & Hendler, James & Lassila, Ora. (2001). The Semantic Web: A New Form of Web Content That is Meaningful to Computers Will Unleash a Revolution of New Possibilities. ScientificAmerican Magazine, May 17, 2001.
INRAE (2026), La Web sémantique et la représentation des connaissances, Vocabulaires Ouverts@INRAE, https://istblogs.d-marheine.com/lovinra/
Magalie Weber
Sonia Bravo
Date de création :